git 実践コマンド集 2026年版【よく使うシーン別まとめ】
git を使って毎日コードを書いているのに「このコマンド、どう書くんだっけ?」と手が止まることはないだろうか。git log のオプションを毎回調べ直す、rebase と merge をどっちにすべか迷う、stash からどう戻すか忘れる——そういった「知ってるようで都度調べる」状態から抜け出すための記事がこれだ。 チームで Git を使う場面を想定し、ブランチ作成からマージ・コンフリクト解消・履歴整理・リモート操作まで、シーン別に実際のコマンドと出力例をセットでまとめた。コピペして使えるレベル ...
agkan完全ガイド:AI Agentと協働するCLIタスク管理ツールの使い方【2026年版】

AIコーディングツール(Claude Code、Cursor、Windsurf等)を使い始めると、避けられない問題に直面する。「AIにタスクを渡したが、前のセッションで何をやっていたか覚えていない」「複数のタスクを並行していると状態管理が追いつかない」という問題だ。 この記事では、まさにその課題のために設計されたCLIツール agkan の使い方を解説する。インストールから基本操作、親子関係・ブロック依存管理、JSON出力を使ったAI連携まで、実際に動かしながら確認した内容をそのまま紹介する。 ...
Developer Experienceとは

近年、DevOpsやCI/CDの世界では開発者エクスペリエンス(DX)が重要視されています。
【2026年最新】AWS ECRにDockerマルチプラットフォームイメージをプッシュする完全手順
AWS ECR(Elastic Container Registry)にDockerのマルチプラットフォームイメージを登録する手順を徹底解説。AWS CLI v2を使った認証設定からbuildxを使ったビルド・プッシュまで、コピペで動くコマンド付きで紹介。
Docker buildxでマルチプラットフォームイメージをAWS ECRにプッシュする完全ガイド【Apple Silicon対応】
docker buildxを使ったマルチプラットフォーム(linux/amd64・linux/arm64)Dockerイメージのビルドから、AWS ECRへのプッシュまでを完全解説。Apple Silicon(M1/M2/M3/M4)Mac環境での実際のコマンドとハマりポイントを詳しく紹介します。
MacでDockerが遅い原因と解決策【2026年版Docker Desktop最適化ガイド】
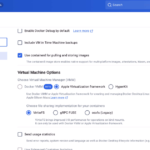
MacでDockerが遅いと感じたらVirtioFS・メモリ・CPU設定の見直しで劇的に改善できます。Docker Desktop 4.x以降の最新機能を使ったApple Silicon(M1/M2/M3/M4)・Intel Mac両対応の具体的な最適化手順を実測データと共に解説します。
リポジトリの運用保守性とコードの可読性・メンテナンス性のバランスについて
こんにちは。今日は、自分の周りではあまり聞かないのですが自分の中にはある、リポジトリの運用保守性について少し考えてみます。 ここで言う運用保守性とは、リポジトリの操作とそれに伴う本番環境への反映などを対象とし、その運用保守性を上げていく対応のことを指しています。 マスターブランチへのマージはrevert出来る状態にしていくブランチ運用で、処理系変更は影響が出るのは当然なのでそこは除外し、処理系変更以外の、リファクタリング等によるrevert時のコンフリクトを極力なくす事を重視します。そこをなくす ...
少数精鋭チームにおける コミット戦略 〜マイクロコミットのすすめ〜
少数精鋭チームとは? 各自が自分の裁量の範囲内で自走出来るチーム 必ずしも優秀なひとが集まっているわけではない メンバーのレベル感を合わせる コミュニケーションコストが低い 極力マネージメントしない 他のメンバーへのサポートを極力少なくする 悪い意味では無く、自走してもらっている分個別に動いてもらった方がパフォーマンスが上がる サポートが必要なメンバーが多いと、周りのパフォーマンスも落ちる =>自走しているとは言えない 相談が必要なところは遠慮無く相談 相談する側のスキルとして、パッとプルリクの ...
システム開発における式年遷宮(しきねんせんぐう)

こんにちは GENDOSUです。 今日は、普段システム開発をしていて、ふと思った事を書いてみます。 式年遷宮(しきねんせんぐう)とは 出典: フリー百科事典『ウィキペディア(Wikipedia)』 式年遷宮をやる主な想定される理由 建築様式を保存するため 神道の精神として、 常に新たに清浄であること (「常若(とこわか)」)を求めたため。 建物がいまだ使用可能の状態であっても、 老朽化することは穢れであり、 神の生命力を衰えさせることとして忌み嫌われたため 他にも色々あるが割愛 これ、システム開 ...
MacBook不要!VPS × Claude Code で作るローカル依存ゼロの開発環境【2026年版完全ガイド】
「ローカルに開発環境を作るのが面倒」「Windowsでの環境構築でいつもつまずく」「Docker for Macが遅すぎる」——このような悩みは、開発環境をリモートサーバーに移すことで根本から解決できます。 このガイドでは、2026年現在の最新ツール構成として VPS(仮想専用サーバー)× Claude Code × VSCode Remote SSH を組み合わせた、ローカルマシン非依存の開発環境を段階的に構築する方法を解説します。 フェーズ1〜3の3段階構成で、あなたの用途とスキルレベルに合 ...
SSHを使って自分だけの開発用サーバのwebアプリケーションに接続する
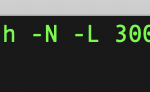
サーバにSSHでトンネルを作ってアクセス出来るようにする。 22番ポートしか空いていないようなサーバで3000番で開発環境を起動してアクセスしたい場合などに使用。 ssh -N -L 3000:localhost:3000 ubuntu@dev アクセスはとすれば、サーバ上のwebアプリケーションの3000番に接続出来る。
git管理したくないエディタの設定とか環境依存ファイルを一括で除外する
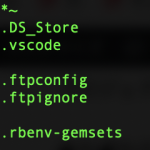
.gitignoreファイル 更新していますか? 扱うプロジェクトが多いと、エディタ変えたときとかプロジェクトディレクトリに設定ファイルを作ってしまうツール等を導入した場合に大変ですね。 今のチームではエディタは各自好きな物を選ぶ運用になっており AtomとかVSCodeとか使っていたりします。 プロジェクトもいくつかありますが それぞれのプロジェクトの.gitignoreに .vscode .atom と言った物を書くのがあまりうれしくないと思ってしまいます。 そんなときは、~/.gitign ...
awsのEC2でswap領域を指定する際のベストプラクティス
awsのEC2では、一部のインスタンスタイプを除いてswap領域が付いていません。 swap領域を設定する方法としては、swap領域用のイメージをファイルで作成してswaponする方法があります。 今回紹介する方法は、awsナイズした方法で、ボリュームを作成してswapとしてマウントさせる方法になります。 通常はストレージとしてのボリュームはボリュームタイプを標準のgp2に設定されていると思うので、それよりも早いプロビジョンドIOPS SSDというボリュームタイプでswapを作成します。 そうす ...
OpenAMをDockerで立ち上げる(俺俺認証編)

SSOやSAMLといった、主に大、中企業向けのID連携の話になります。
Redis Desktop Manager(rdm)をソースからビルドしよう(mac版)
ちょっと前、Redis Desktop Manager(rdm)はオープンソースで、バイナリも無料で配布されていました。 今は、有料プランになってしまいました。 Contributorプランがあるのは面白いですね。 プルリクエストを送って、マージされたら1年間使えるということのようです。 課金しても良いんですが エンジニア、せっかくなのでコントリビュートすることを目指して まずはビルドできる環境を作ってみましょう。 まずは公式のBuild from sourceを参照します。 手順が実に短いです ...
Docker容量削減の完全ガイド【system prune・イメージ削除・ボリューム掃除】

Dockerを使い続けると、気づかないうちにディスク容量が逼迫していく。「MacBookのSSDがいっぱいになってきた」「docker system dfを見たら20GB以上も消費している」という経験をしたことがあるエンジニアは多いはずだ。 このガイドでは、Dockerによるディスク圧迫を安全に・確実に解消するための手順を体系的に解説する。闇雲にdocker system pruneを実行して必要なコンテナを消してしまった失敗談も含めながら、段階的なアプローチを紹介する。 筆者自身、以前は28イ ...
es6でランダムに文字列を生成するロジックを考えてみる
es6では、Array.fromで、配列の数分ループを回せるので 回したい回数分の配列を作成して、Array.fromに渡します。 コールバックでは使用する文字列からランダムに 一文字を抽出する処理をループさせ、 出来上がった配列をjoinすれば ランダムな文字列が完成します。 let digit = 12; // 生成したい文字数 let alArray = ‘abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789’; // ...
gooseをdockerイメージにした話
gooseというgoで書かれたDBマイグレーションツールがあり、これだけを含んだDockerイメージを作った。 hub.docker.comにアップしてあるので run --rm -v `pwd`:/go gendosu/goose goose create example でという感じで実行出来る。
git clone ブランチ指定の完全ガイド【-b・–depth・sparse-checkout 2026年版】
git clone でブランチを指定するには -b オプションを使います。git clone -b ブランチ名 URL の基本から、--depth 1 で高速クローンする方法、タグ・コミット指定まで実例付きで徹底解説します。
herokuでMemory Quota Exceededと言うのが出るようになったので、puma_worker_killerを入れた話
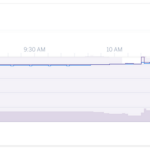
最近、herokuで稼働させているRailsのアプリが「Memory Quota Exceeded」と言われる事が多くなり、定期的にワーカーの再起動をしたいと思ってました。 見る限り、swapも出てしまい、レスポンスも遅くなっているようです。 このような場合、heroku以外だと、unicornを使うので、unicorn_worker_killerを入れるのですが herokuだとpuma推薦なのでpuma使っていました。 で、pumaもuniconのようにworker killer系の物がある ...